change_tracking feature extracts strikethroughs, underlines, and annotations from redlined contracts as structured HTML tags—making it easy to list changes programmatically, categorize by type, and build approval workflows.
What you’ll build
By the end of this cookbook, you’ll have a pipeline that parses any redlined contract and extracts every revision as structured data.Create API Key
1
Open Studio
Go to studio.reducto.ai and sign in. From the home page, click API Keys in the left sidebar.
2
View API Keys
The API Keys page shows your existing keys. Click + Create new API key in the top right corner.
3
Configure Key
In the modal, enter a name for your key and set an expiration policy (or select “Never” for no expiration). Click Create.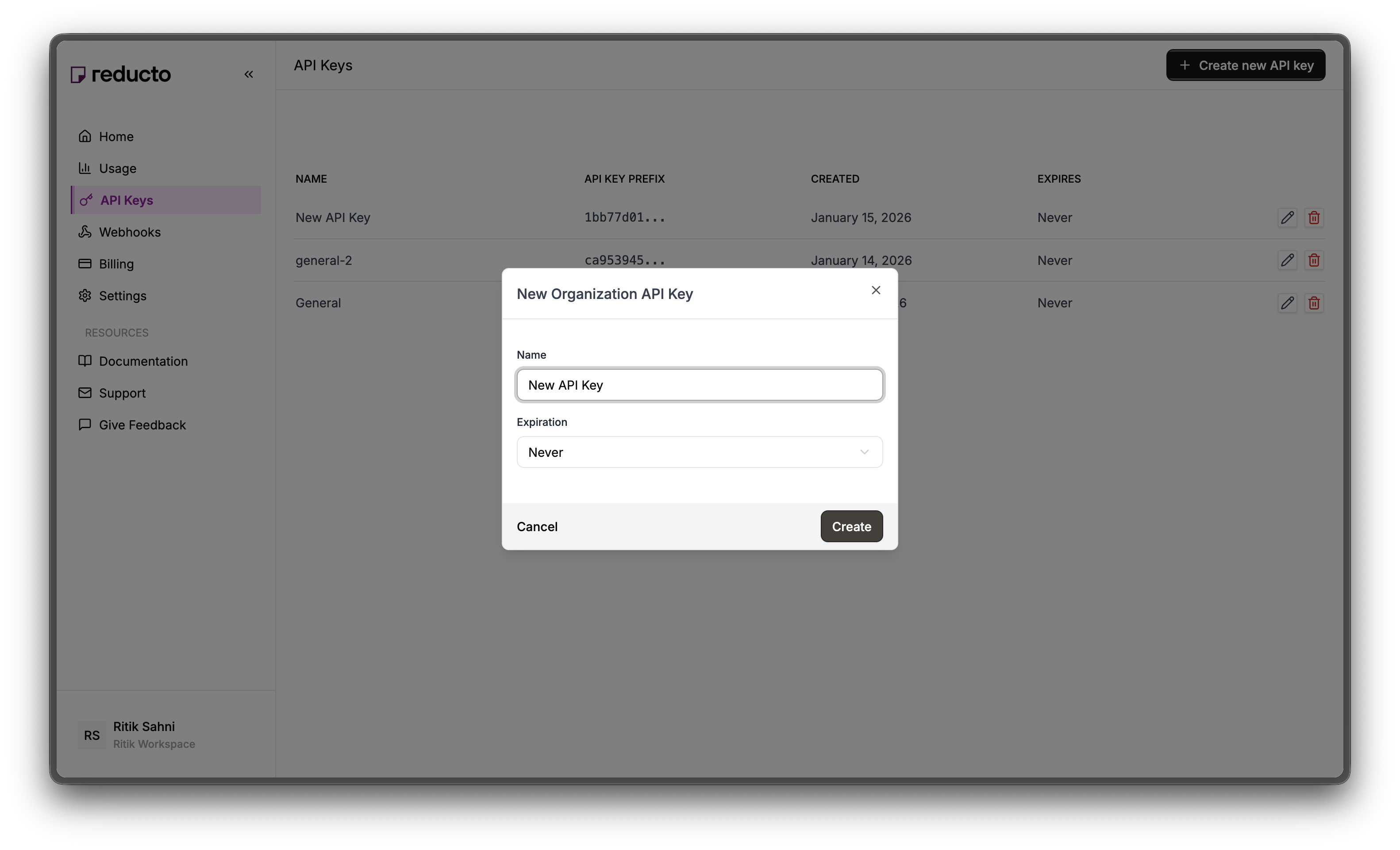
4
Copy Your Key
Copy your new API key and store it securely. You won’t be able to see it again after closing this dialog.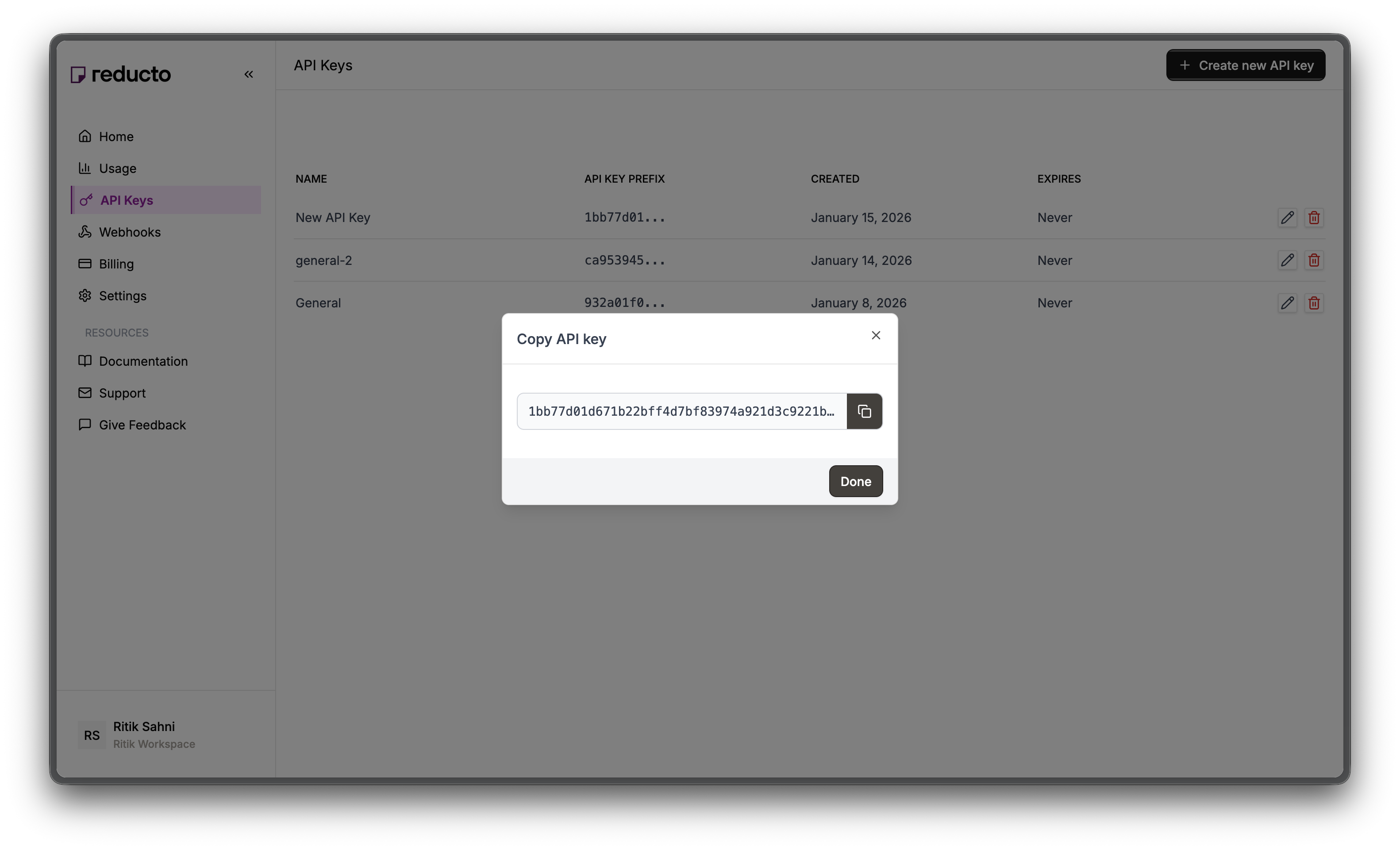
Sample document
For this cookbook, we use a 165-page union labor agreement (AFSCME Local 328 vs. Oregon Health & Science University) with extensive redlines showing proposed contract changes. The document includes:- Strikethroughs for deleted clauses
- Underlines for new language
- Inline annotations explaining changes
Step 1: Parse with change tracking
Upload the document
First, upload your redlined contract to Reducto:Parse with change tracking enabled
The key setting isformatting.include: ["change_tracking"]. This tells Reducto to detect underlines and strikethroughs and wrap them in HTML tags.
change_tracking?
Without this option, Reducto returns plain text. With it enabled, revisions appear as HTML tags that you can parse programmatically:
<s>wraps strikethrough text (deletions)<u>wraps underlined text (insertions)<change>groups related revisions together
Step 2: Handle large documents
For large documents like our 165-page contract, Reducto returns results as a URL rather than inline data. This keeps response sizes manageable.Step 3: Understand the output
With change tracking enabled, revisions appear as HTML markup in the content. Here’s what we found in our sample contract:Real examples from the document
Simple insertion (new language added):Tag meanings
A single
<change> block can contain:
- Just a deletion:
<change><s>removed text</s></change> - Just an insertion:
<change><u>new text</u></change> - Both:
<change><s>old</s> <u>new</u></change>
Step 4: Extract changes programmatically
Now we parse the HTML tags to get a structured list of all changes. This function uses regex to find every<change> block and extract the deletions and insertions within it.
Run the extraction
Step 5: Categorize changes
Not all changes are equal. Some are pure deletions (language removed), some are pure insertions (new language added), and some are replacements (old swapped for new). Categorizing helps prioritize review.Using Studio
You can also extract changes visually in Reducto Studio without writing code.1
Upload your document
Go to studio.reducto.ai and upload your redlined contract.
2
Enable change tracking
In the Configurations tab, switch to Advanced mode. Expand the Formatting section and check 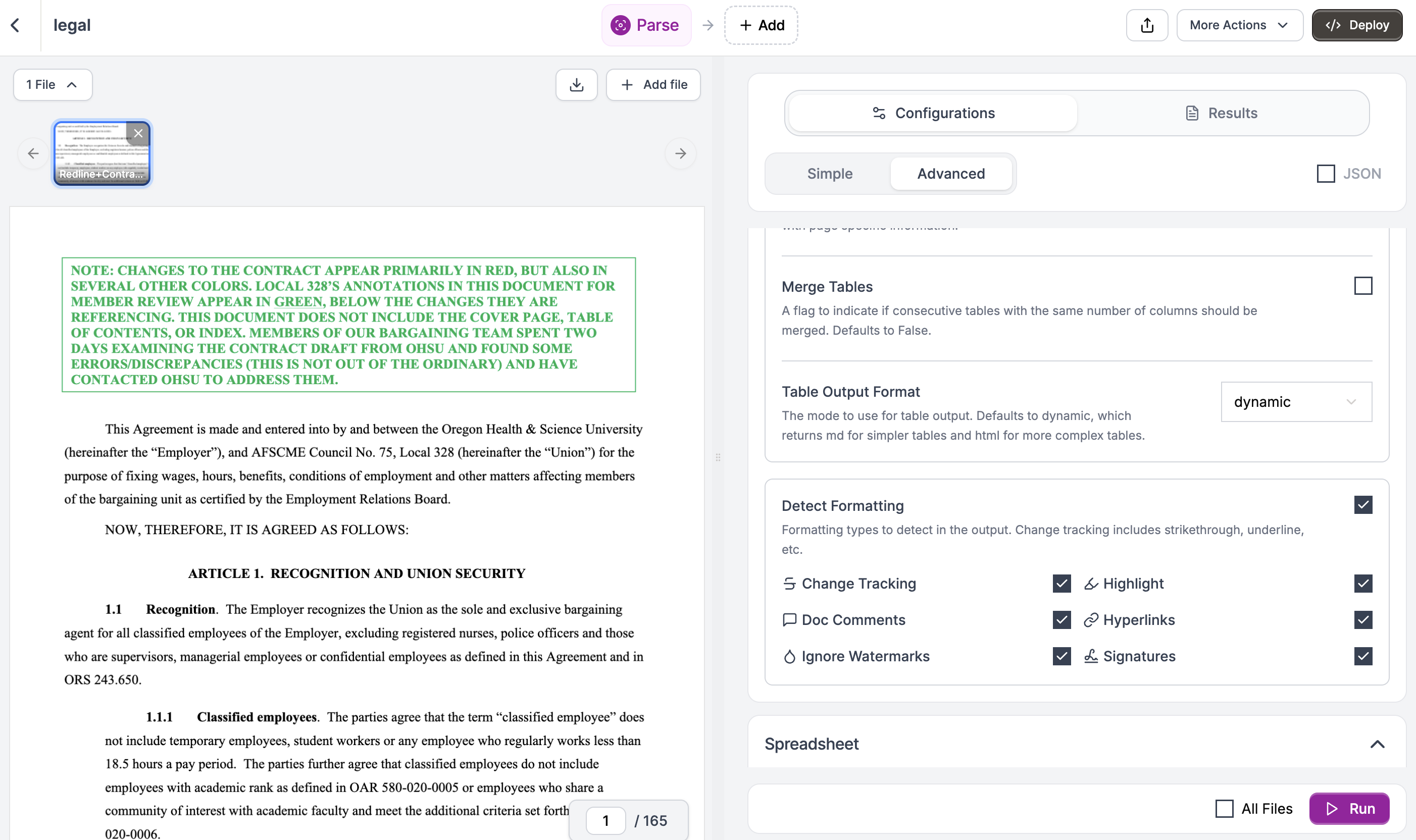
change_tracking.3
Run and review
Click Run. The results show the parsed content with
<change>, <s>, and <u> tags visible in the output. You can search for specific changes using Ctrl+F.4
Export or deploy
Copy the results, download as JSON, or deploy the pipeline with these settings for repeated use on similar documents.
Complete example
Here’s a full script that parses a redlined contract and generates a change summary:How change tracking works
Reducto uses different detection methods depending on document type:For best results, use Word documents with Track Changes enabled. The metadata is preserved natively. PDFs require visual detection, which works well but depends on clear formatting.
Best practices
Use Word documents when possible
Use Word documents when possible
Word’s native Track Changes stores revision metadata directly in the file. This gives Reducto exact information about what was added or removed, including author and timestamp. PDFs require visual detection.
Categorize changes for efficient review
Categorize changes for efficient review
Replacements (where old text is swapped for new) often need careful review. Pure insertions may be less risky. Route different categories to appropriate reviewers.
Combine with Extract for clause analysis
Combine with Extract for clause analysis
Use Parse with change tracking to get the revisions, then pipe specific clauses through Extract to pull structured fields like dates, amounts, or party names.
Handle nested changes carefully
Handle nested changes carefully
Some documents have nested revisions (changes within changes). The regex patterns above handle simple cases. For complex documents, consider using an HTML parser like BeautifulSoup.
Use cases
Contract review automation
Contract review automation
Extract all changes from incoming redlines and route them to the appropriate reviewer based on clause type. Send indemnification changes to legal, pricing changes to finance.
Change approval workflows
Change approval workflows
Build approval queues where each revision must be explicitly accepted or rejected before finalizing the agreement. Track who approved what.
Compliance tracking
Compliance tracking
Monitor changes to policies and procedures. Flag modifications to critical sections for compliance review before they go into effect.
Negotiation summaries
Negotiation summaries
Generate executive summaries showing what the counterparty changed. Brief stakeholders without requiring them to read a 165-page document.
Next steps
Additional Document Data
Learn about highlights, hyperlinks, and signatures.
Extract
Pull structured data from specific clauses.
Batch Processing
Process multiple contracts in parallel.
Studio Guide
Visual walkthrough of the Parse pipeline.