Extract policy data from declarations pages and fill ACORD 25 certificates
ACORD 25 is the standard certificate of liability insurance in the US. Agencies issue hundreds daily, pulling data from policy declarations pages. This cookbook extracts declarations data and maps it to ACORD 25 fields.
The ACORD 25 is a standardized form with specific field locations for policy numbers, coverage limits, and dates. The Edit API detects these fields automatically.
The declarations page contains all policy details: insured name, policy numbers, effective dates, and coverage limits. This is the source data we’ll extract.
The declarations page contains all the policy details needed to fill an ACORD 25: insured name, policy number, effective/expiration dates, and coverage limits.
Go to studio.reducto.ai and create an Extract pipeline. Upload the declarations page PDF.Extract reads the document and lets you define a schema to pull specific fields as structured JSON.
2
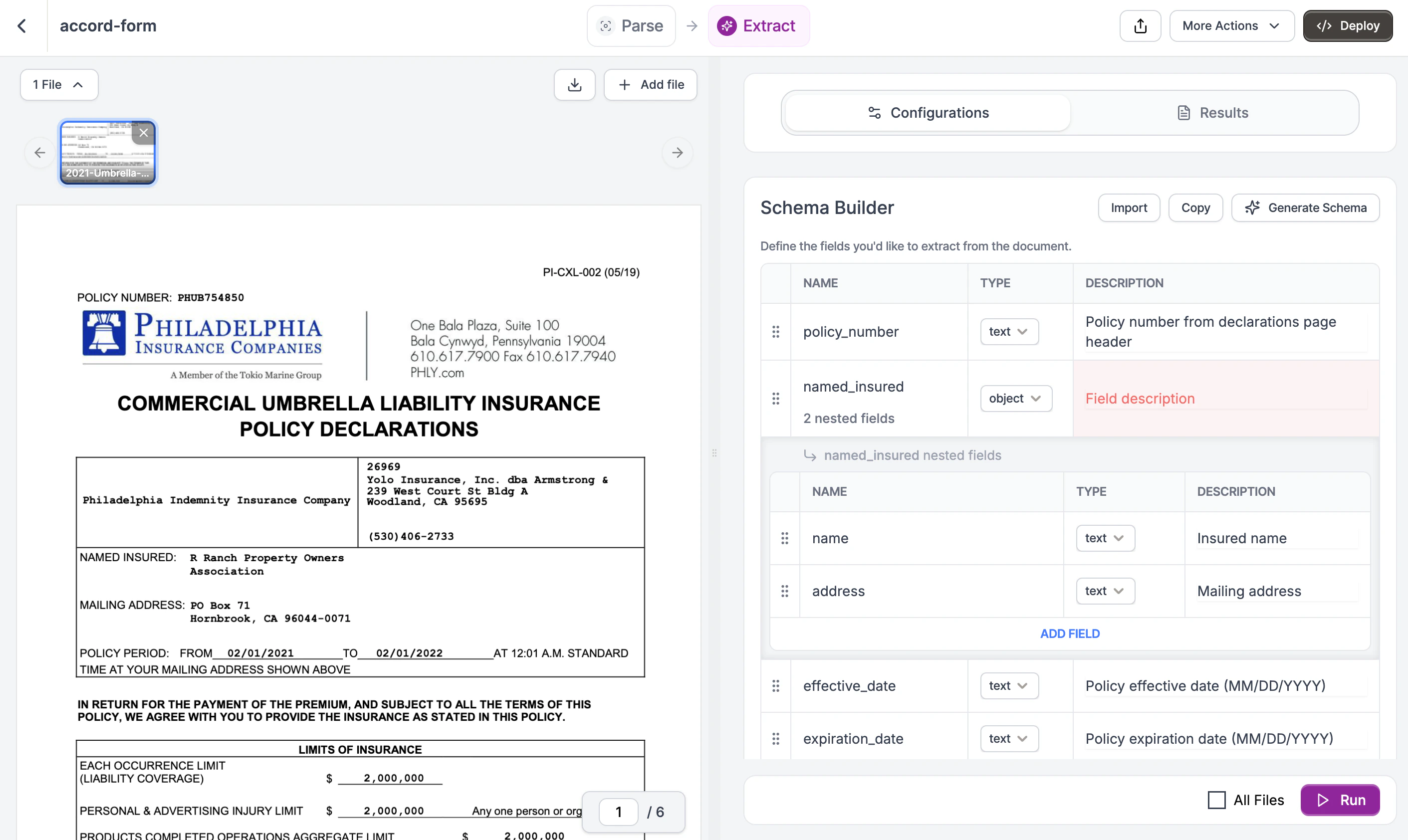
Build the Schema
In the Schema Builder, define fields matching the declarations page structure. Click Add Field for each:
policy_number (text) - “Policy number from the declarations page”
Schema Builder with declarations page fields defined
Field descriptions help the LLM locate the right values. Be specific about where each field appears. See the Complete Schema below for a copy-paste version.
3
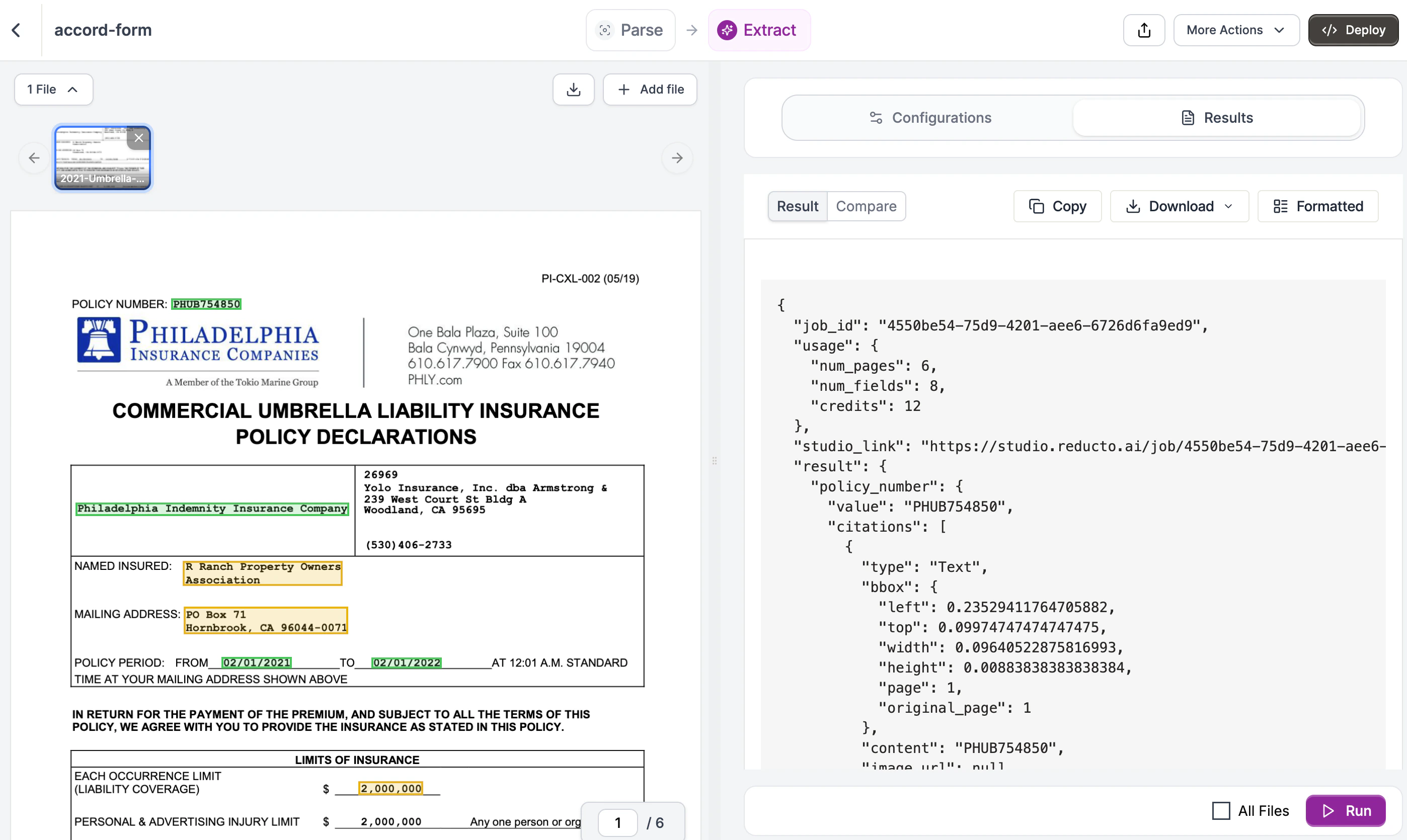
Run Extraction
Click Run. The Results tab shows extracted data as JSON:
Upload the declarations page PDF. This returns a file_id that you’ll use for extraction. Reducto stores the file temporarily so you can process it without re-uploading.
from pathlib import Pathupload = client.upload(file=Path("declarations.pdf"))print(f"Uploaded: {upload.file_id}")
Add the basic policy fields. Each field needs a type and a description. The description is important because it tells the LLM where to find the value.
declarations_schema = { "type": "object", "properties": { "policy_number": { "type": "string", "description": "Policy number from declarations page header" }, "effective_date": { "type": "string", "description": "Policy effective date (MM/DD/YYYY)" }, "expiration_date": { "type": "string", "description": "Policy expiration date (MM/DD/YYYY)" }, "insurer_name": { "type": "string", "description": "Insurance company name" } }}
const declarationsSchema = { type: "object", properties: { policy_number: { type: "string", description: "Policy number from declarations page header" }, effective_date: { type: "string", description: "Policy effective date (MM/DD/YYYY)" }, expiration_date: { type: "string", description: "Policy expiration date (MM/DD/YYYY)" }, insurer_name: { type: "string", description: "Insurance company name" } }};
{ "type": "object", "properties": { "policy_number": { "type": "string", "description": "Policy number from declarations page header" }, "effective_date": { "type": "string", "description": "Policy effective date (MM/DD/YYYY)" }, "expiration_date": { "type": "string", "description": "Policy expiration date (MM/DD/YYYY)" }, "insurer_name": { "type": "string", "description": "Insurance company name" } }}
Why descriptions matter: “Policy number” alone is ambiguous if the page has multiple numbers. Adding “from declarations page header” helps the LLM find the right one.
The extracted data is in result.result[0] (the API returns an array for multi-document support). Each field from your schema becomes a key in the response:
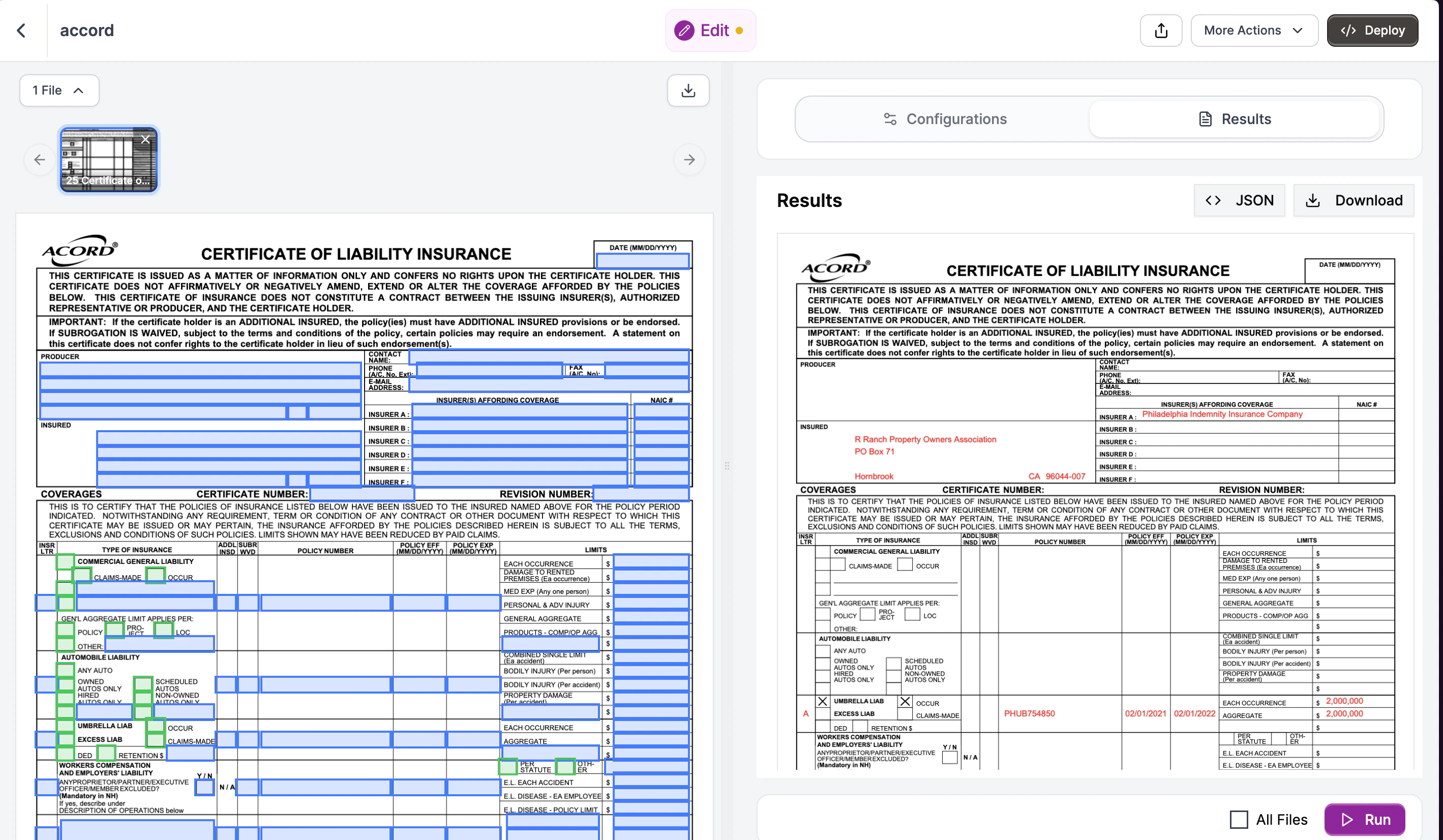
Use the extracted policy data to fill a blank ACORD 25 certificate. The Edit API detects form fields and fills them based on natural language instructions.
Create an Edit pipeline in Studio. Upload a blank ACORD 25 PDF.Edit detects all fillable fields in the form: text boxes, checkboxes, and dropdowns.
2
Write Fill Instructions
In the Edit Instructions panel, describe what values to fill. Reference the data you extracted:
Fill this ACORD 25 Certificate with:INSURED:- Name: R Ranch Property Owners Association- Address: PO Box 71, Hornbrook, CA 96044-0071INSURER A:- Company: Philadelphia Indemnity Insurance CompanyUMBRELLA LIABILITY:- Policy Number: PHUB754850- Effective: 02/01/2021- Expiration: 02/01/2022- Each Occurrence: $2,000,000- Aggregate: $2,000,000- Check "Occurrence" for policy type
Be explicit about field locations when the form has similar fields (e.g., multiple policy number boxes).
3
Run and Download
Click Run. Edit fills the form and returns a download link. The filled PDF has all your values in the correct fields.
Edit uses natural language instructions instead of a schema. Describe what values should go where. Reference the section names on the form to help Edit find the right fields.
instructions = f"""Fill this ACORD 25 Certificate of Liability Insurance with:INSURED:- Name: {policy_data['named_insured']['name']}- Address: {policy_data['named_insured']['address']}INSURER A:- Company: {policy_data['insurer_name']}UMBRELLA LIABILITY SECTION:- Policy Number: {policy_data['policy_number']}- Effective Date: {policy_data['effective_date']}- Expiration Date: {policy_data['expiration_date']}- Each Occurrence limit: ${policy_data['umbrella_occurrence_limit']:,}- Aggregate limit: ${policy_data['umbrella_aggregate_limit']:,}- Check the "Occurrence" checkbox for umbrella policy type"""
const instructions = `Fill this ACORD 25 Certificate of Liability Insurance with:INSURED:- Name: ${policyData.named_insured.name}- Address: ${policyData.named_insured.address}INSURER A:- Company: ${policyData.insurer_name}UMBRELLA LIABILITY SECTION:- Policy Number: ${policyData.policy_number}- Effective Date: ${policyData.effective_date}- Expiration Date: ${policyData.expiration_date}- Each Occurrence limit: $${policyData.umbrella_occurrence_limit.toLocaleString()}- Aggregate limit: $${policyData.umbrella_aggregate_limit.toLocaleString()}- Check the "Occurrence" checkbox for umbrella policy type`;
# Build the instructions string with extracted valuesINSTRUCTIONS="Fill this ACORD 25 with: INSURED Name: R Ranch Property Owners Association, Address: PO Box 71, Hornbrook, CA 96044-0071. INSURER A: Philadelphia Indemnity Insurance Company. UMBRELLA LIABILITY: Policy Number PHUB754850, Effective 02/01/2021, Expiration 02/01/2022, Each Occurrence \$2,000,000, Aggregate \$2,000,000, check Occurrence checkbox."
Why natural language? ACORD forms have cryptic field names like topmostSubform[0].Page1[0].f1_1[0]. Edit uses AI to understand context, so “Insured Name” works even if the PDF field is named something obscure.
ACORD 25 has multiple checkbox fields (policy types, coverage indicators). Be explicit in your instructions:
edit_instructions = """Check the "Occurrence" checkbox in the Umbrella Liability section.Check "Any Auto" in the Auto Liability section.Leave all other checkboxes unchecked."""