Sample Document
Download the sample: un-document-spanish.pdf
Supported Languages
Reducto automatically detects and processes these languages:View all 60+ supported languages
View all 60+ supported languages
Create API Key
1
Open Studio
Go to studio.reducto.ai and sign in. From the home page, click API Keys in the left sidebar.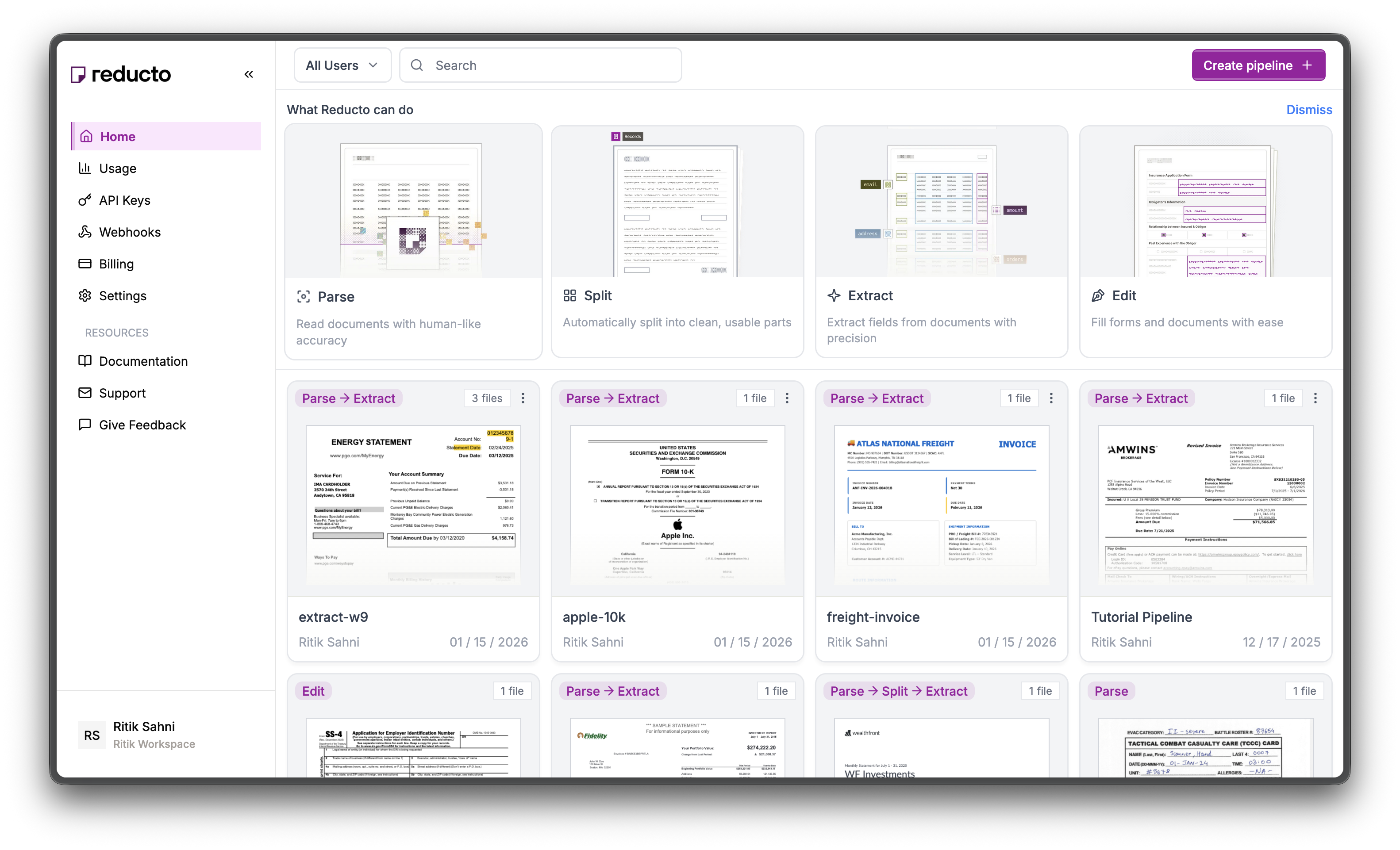
2
View API Keys
The API Keys page shows your existing keys. Click + Create new API key in the top right corner.
3
Configure Key
In the modal, enter a name for your key and set an expiration policy (or select “Never” for no expiration). Click Create.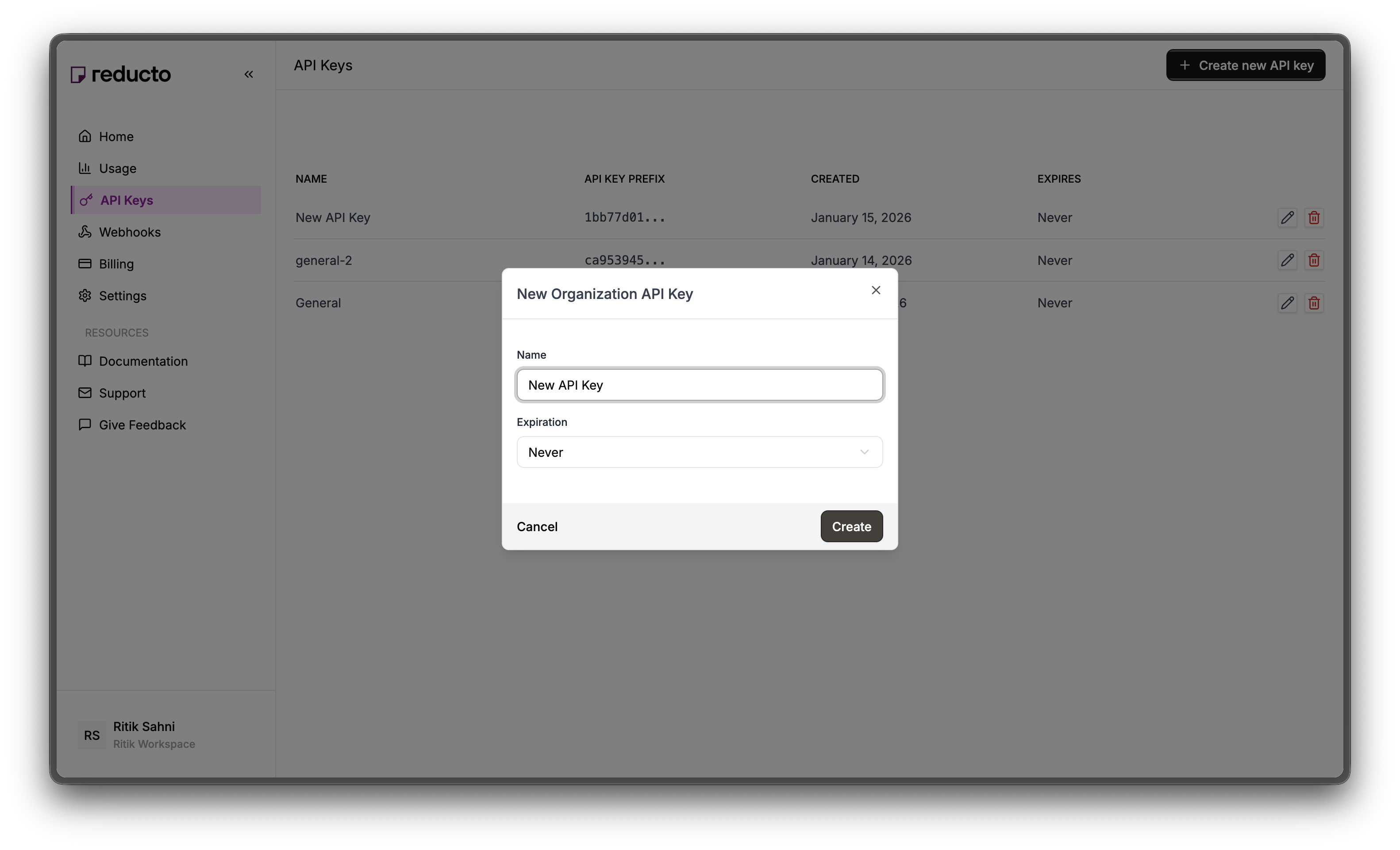
4
Copy Your Key
Copy your new API key and store it securely. You won’t be able to see it again after closing this dialog.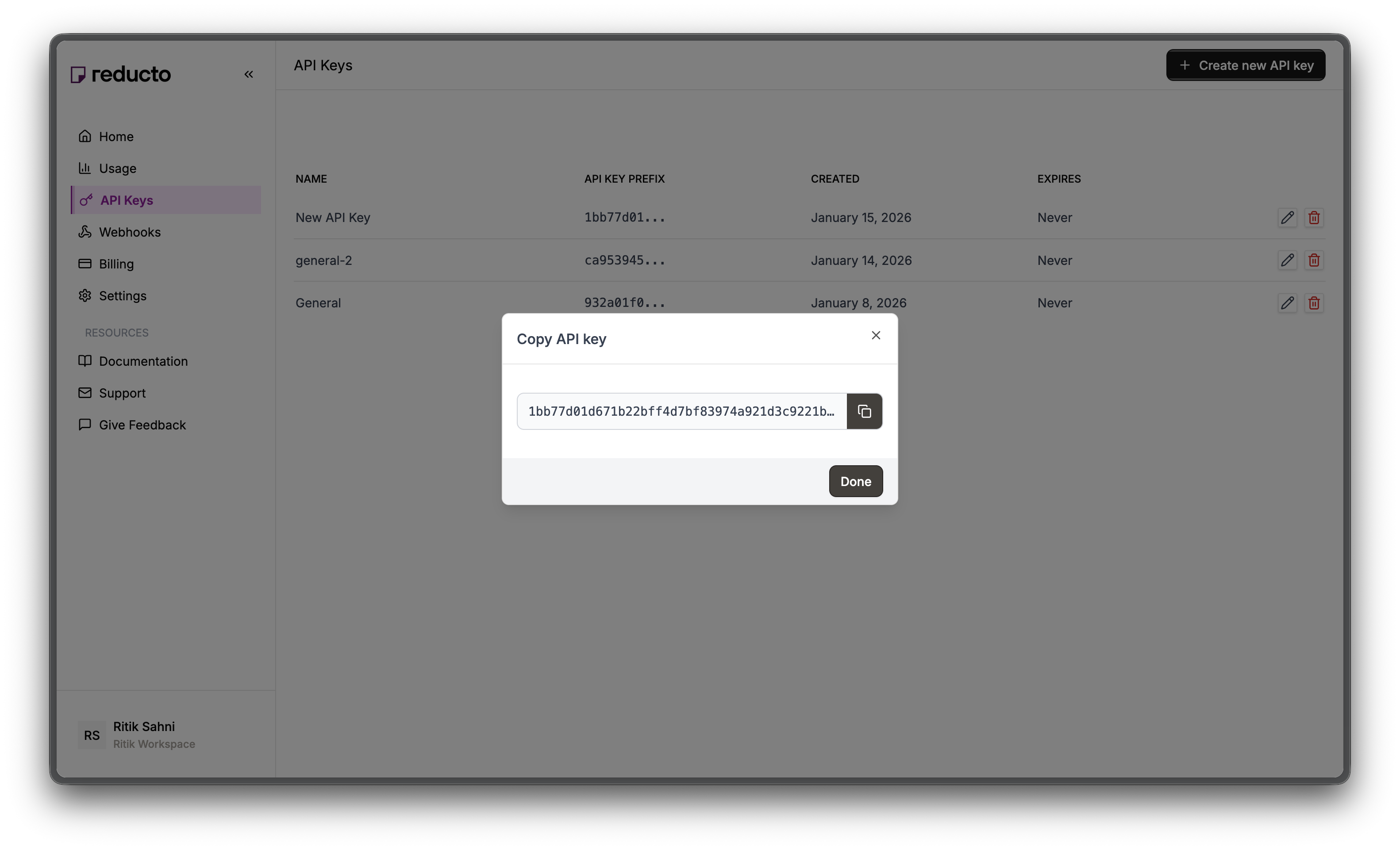
Studio Walkthrough
1
Upload and Configure OCR
Upload your multilingual document to studio.reducto.ai. In the Parse view, open the Configurations tab to see OCR settings.
- Extraction Mode: Use
ocrfor scanned documents where text is embedded as images. Usehybrid(default) for mixed documents where some pages are native text and others are scans. - OCR System: Keep
standard(default) for 60+ language support. Thelegacysystem only supports Germanic languages.
2
View Extracted Text
Click Run and switch to the Results tab. Reducto extracts text in the original language with proper character encoding.
Processing Non-English Documents
Basic Usage
No special configuration needed - just parse as usual:Output Example
From a Spanish UN Security Council document:OCR Configuration Options
Extraction Modes
Choose the right mode for your document type:OCR System Selection
Always usestandard for multilingual support:
Mixed-Language Documents
Documents containing multiple languages are handled automatically:Example: Bilingual Contract
Agentic Mode for Difficult Text
Standard OCR works well for clean, printed documents. For challenging documents like handwriting, faded text, or unusual fonts, agentic mode uses a vision language model to verify and correct OCR output.- Text is handwritten or uses decorative fonts
- Document is faded, stained, or low quality
- OCR produces garbled output on first pass
Agentic mode costs approximately 2x credits. Use it selectively for documents where standard OCR struggles.
Extracting Structured Data
Extract structured data from non-English documents using schemas with descriptive field hints:Tips
For best results with non-English documents:- Use high-quality scans (300 DPI minimum) for better OCR accuracy
- Enable agentic mode for handwritten or degraded text
- Provide bilingual field descriptions in extraction schemas to improve accuracy
- Use
extraction_mode: "ocr"for scanned documents instead of relying on embedded text
Next Steps
OCR Settings
Full OCR configuration reference
Agentic Modes
AI-enhanced text correction
Batch Processing
Process many documents at scale
Extract API
Structured data extraction