Sample Documents
- ID Card
- Utility Bill
- W-9 Form

- Name: IMA CARDHOLDER
- Address: 2570 24TH STREET, ANYTOWN, CA 95818
- DOB: 08/31/1977
- DL Number: 11234568
Download samples: id-card.png | utility-bill.pdf | w9-form.pdf
{kind=link}
- Name case: “IMA CARDHOLDER” (ID) vs “Ima Cardholder” (W-9)
- City spelling: “ANYTOWN” (ID) vs “Andytown” (utility bill)
- Street format: “24TH STREET” vs “24th Street”
Create API Key
1
Open Studio
Go to studio.reducto.ai and sign in. From the home page, click API Keys in the left sidebar.
2
View API Keys
The API Keys page shows your existing keys. Click + Create new API key in the top right corner.
3
Configure Key
In the modal, enter a name for your key and set an expiration policy (or select “Never” for no expiration). Click Create.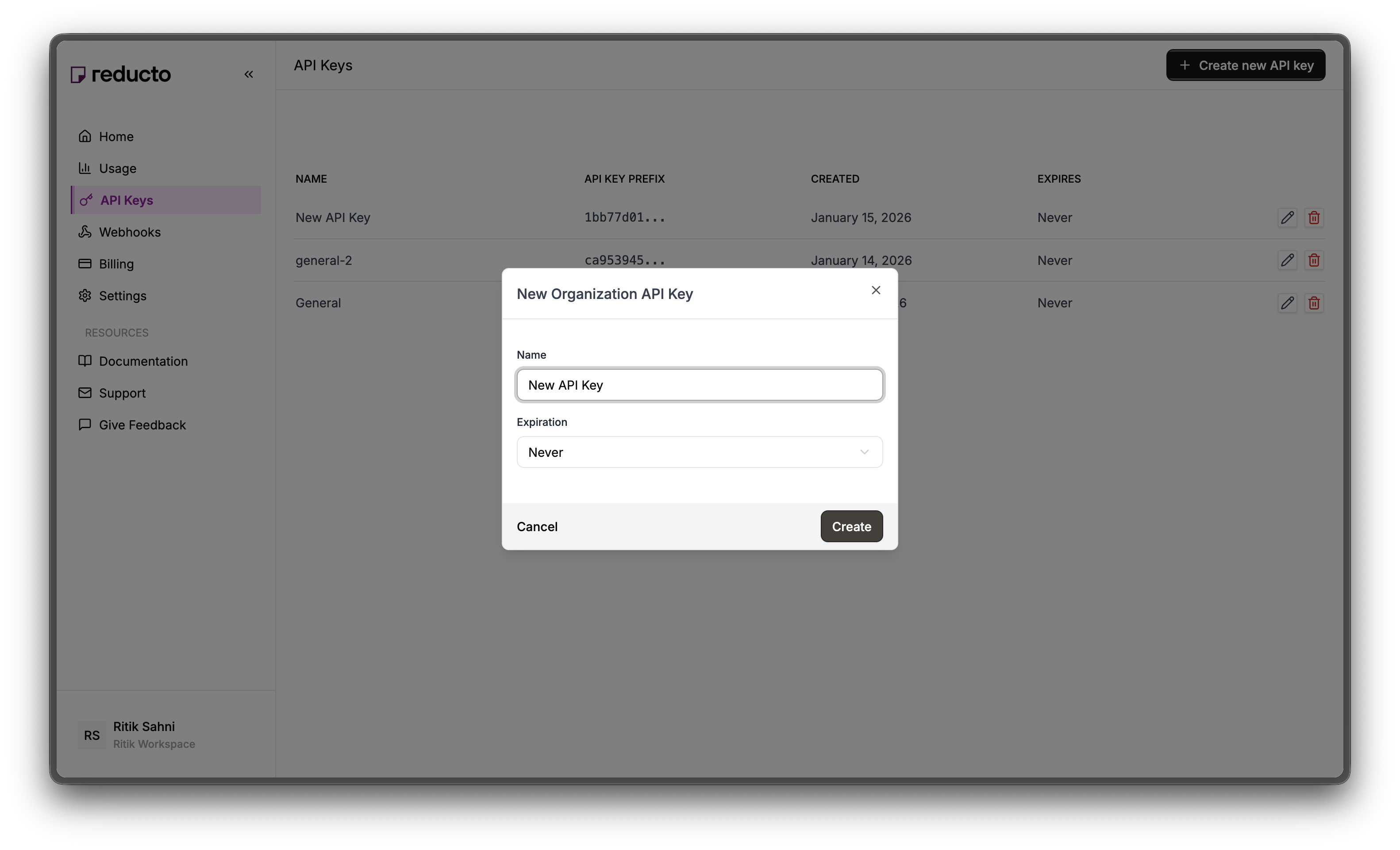
4
Copy Your Key
Copy your new API key and store it securely. You won’t be able to see it again after closing this dialog.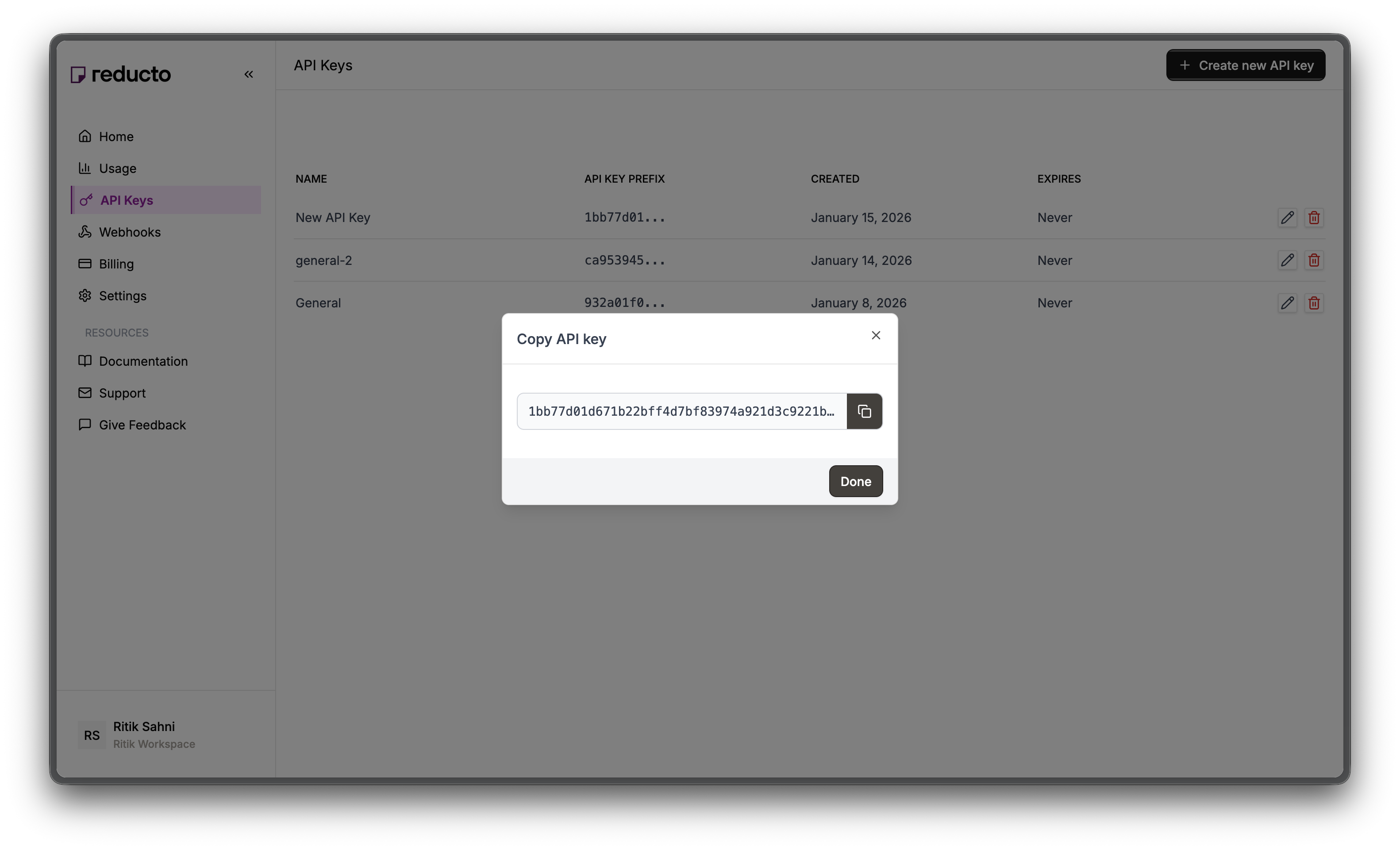
Verification Workflow
1
Upload Documents
User submits ID card, utility bill, and W-9 form
2
Extract Data
Reducto extracts name, address, and identifiers from each document
3
Normalize Fields
Standardize names and addresses for comparison
4
Cross-Match
Compare fields across documents to verify consistency
5
Return Result
Pass or fail based on matching criteria
Step 1: Define Extraction Schemas
Each document type needs a tailored schema. The key is writing good field descriptions that tell the LLM where to find each value.ID Card Schema
Government IDs have structured layouts with clear field labels. We extract both identity fields and the ID’s validity period.full_nameandfirst_name/last_name: Extract both because other documents may format names differentlydate_of_birthformat: Request YYYY-MM-DD for consistent date handling in codeexpiration_date: Critical for checking if the ID is still valid
Utility Bill Schema
Utility bills prove current address. They vary more in layout than IDs, so field descriptions need to be more specific about what to extract.account_holder: This is what we match against the ID nameservice_address(not mailing address): The service address proves residencestatement_date: Bills must be recent (typically within 90 days)
W-9 Tax Form Schema
W-9s have a fixed IRS layout. Field descriptions reference specific line numbers to help the LLM locate values.city_state_zipas one field: W-9 Line 6 combines these, so we extract them together and parse later- Line number references: “Line 1”, “Line 5”, “Line 6” help the LLM find the right fields on the standardized IRS form
Step 2: Extract from All Documents
Upload each document and run extraction with the appropriate schema. Reducto handles both image files (ID card) and PDFs (utility bill, W-9) with the same API.Extraction Results
From our sample documents:- Name: “IMA CARDHOLDER” vs “Ima Cardholder” (case difference)
- City: “ANYTOWN” vs “Andytown” (case + typo)
- Street: “24TH STREET” vs “24th Street” (case + abbreviation)
Step 3: Normalize and Compare
Extracted data won’t match exactly across documents. Here’s what we see:
These are clearly the same person at the same address, but string comparison would fail.
Normalization Functions
Normalization standardizes these variations:- Uppercase everything
- Convert abbreviations (“STREET” → “ST”)
- Remove punctuation
- Collapse extra whitespace
- “IMA CARDHOLDER” → “IMA CARDHOLDER”
- “Ima Cardholder” → “IMA CARDHOLDER” ✓ Match!
- “2570 24TH STREET” → “2570 24TH ST”
- “2570 24th Street” → “2570 24TH ST” ✓ Match!
Why Fuzzy Matching?
Even after normalization, OCR errors and typos happen. “ANYTOWN” vs “ANDYTOWN” is a single character difference. It’s likely the same city, not a fraudulent mismatch. Fuzzy matching with an 85% similarity threshold catches these while rejecting genuine mismatches:Step 4: Verification Strategy
Our verification uses two tiers of checks: Critical checks (must pass):- Name match - Name must match across all three documents
- Address match - Address must match (street, state, ZIP)
Implementing Name Matching
Compare normalized names across all document pairs. All three must match:Implementing Address Matching
Address matching is trickier. We check street, state, and ZIP separately. The W-9 combines city/state/zip into one field, so we parse it first.Document Validity Checks
These are warnings, not blockers. An expired ID or old utility bill should be flagged but may not fail verification outright.Complete Verification Function
Combine all checks and calculate the result:Step 5: Run Verification
Verification Output (Sample Documents)
Complete Example
Tips
Handling verification failures
Build user-friendly error messages that tell users exactly what to fix:Async processing for scale
For high-volume verification, use async extraction to process documents in parallel:Compliance considerations
Next Steps
Extract Overview
Learn about structured extraction
Image Processing
Reducto supports images and PDFs
Async Processing
Scale to high volumes
Batch Processing
Process many verifications