Create Reducto API Key
1
Open Studio
Go to studio.reducto.ai and sign in. From the home page, click API Keys in the left sidebar.
2
View API Keys
The API Keys page shows your existing keys. Click + Create new API key in the top right corner.
3
Configure Key
In the modal, enter a name for your key and set an expiration policy (or select “Never” for no expiration). Click Create.
4
Copy Your Key
Copy your new API key and store it securely. You won’t be able to see it again after closing this dialog.
Prerequisites
You’ll also need accounts and API keys from these services:
You’ll also need a vision-capable LLM (Claude, GPT-4V, Gemini, etc.) for the final generation step.
Install the required packages:
Setup: AWS S3 bucket
We need an S3 bucket to store extracted images permanently. Reducto’s image URLs expire after 1 hour for security reasons. If we stored those URLs directly in our vector database, they’d be broken by the time someone queries the system tomorrow. S3 gives us permanent, publicly-accessible URLs that work indefinitely.1
Create an IAM user
Never use your AWS root account for applications. Instead, create a dedicated IAM user with limited permissions.Go to IAM Console → Users → Create user.
2
Attach S3 permissions
Select Attach policies directly, search for
AmazonS3FullAccess, check it, and click Create user.This gives the user permission to read and write to S3 buckets, but nothing else in your AWS account.3
Create access keys
Click on your new user → Security credentials → Create access key.Select “Command Line Interface (CLI)”, confirm, and create.Save both keys now - you won’t see the secret again. You’ll need these for the
AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables.4
Create an S3 bucket
Go to S3 Console → Create bucket.
my-multimodal-rag-images) and select a region close to you for lower latency.5
Enable public access
By default, S3 buckets are private. We need to make objects publicly readable so your application can fetch images at query time.In your bucket → Permissions tab:First, disable the block public access settings:Replace
-
Click Block public access → Edit → Uncheck all 4 boxes → Save
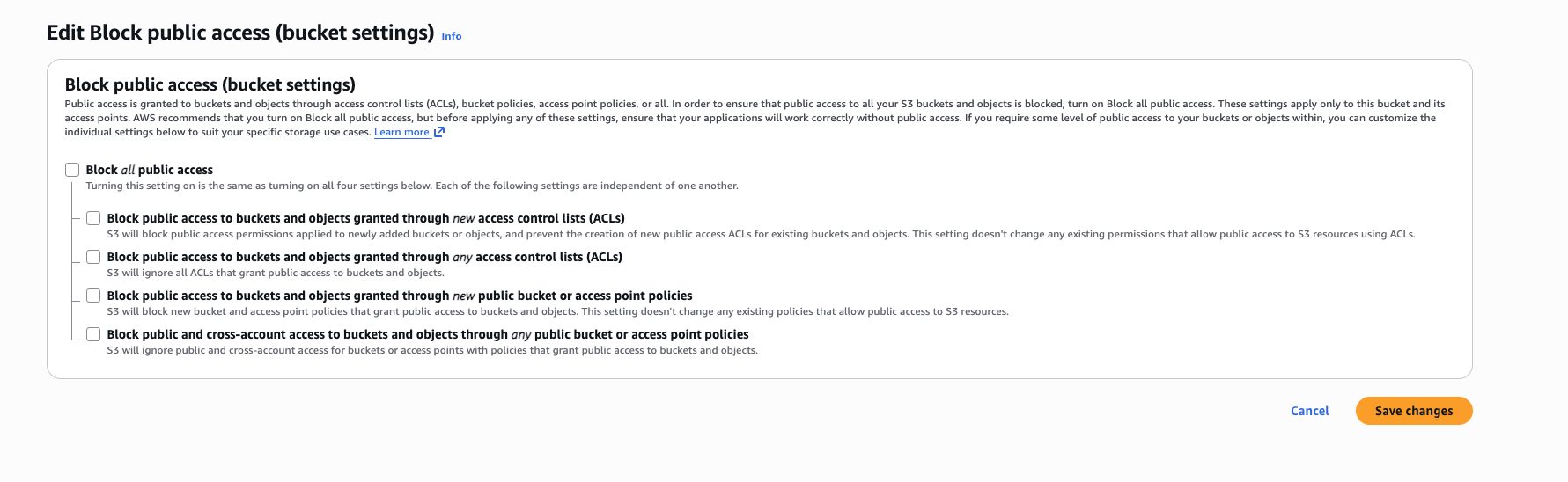
- Click Bucket policy → Edit → Paste this policy:
YOUR-BUCKET-NAME with your actual bucket name.Setup: Pinecone index
We need a vector index to store text embeddings. Each vector will also include metadata with the S3 URL, so we can fetch the corresponding image at query time.1
Create index
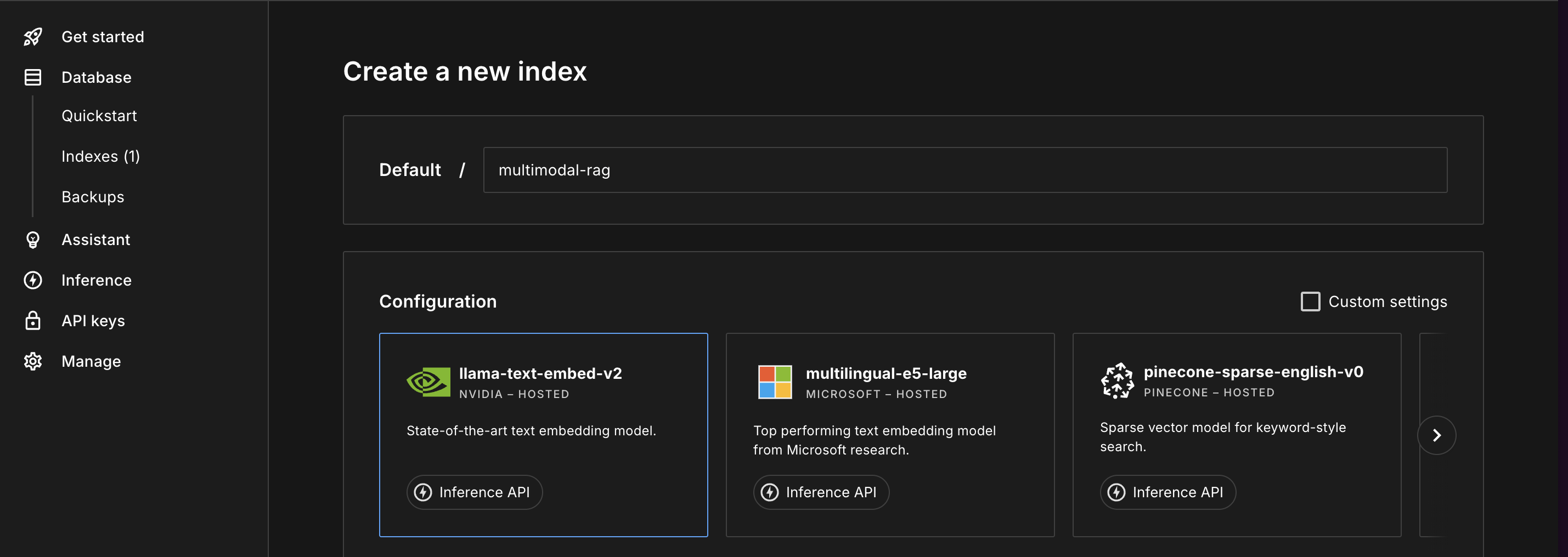
- Name:
multimodal-rag - Dimensions:
1024(this must match VoyageAI’s voyage-3 model) - Metric:
cosine
Set environment variables
Before running any code, set these environment variables in your terminal:Sample document
For this cookbook, we’ll use an open-access research paper from PubMed Central about hepatitis B treatment. This paper has 16 pages with multiple figures, charts, and data tables, making it ideal for demonstrating multimodal RAG.
research_paper.pdf in your working directory.
Step 1: Parse the document with image extraction
Initialize the client
First, we create a Reducto client using our API key:Upload the document
Before parsing, we need to upload the file to Reducto’s servers. Theupload() method returns a file ID that we’ll use in the parse call:
Parse with image extraction
Now we parse the document. The key settings here are:return_images: Tells Reducto to crop and return images for figures and tableschunk_mode: Controls how text is grouped into chunks
chunk_mode: "section"?
We use section-based chunking because it keeps figures together with their surrounding explanatory text. If a figure appears in the “Results” section, the chunk will include both the figure and the text that explains it. This improves retrieval quality because the embedding captures the full context.
Other options:
page: One chunk per page. Simpler but may split related content.variable: Adaptive chunking based on content density.
Step 2: Understand the response structure
Before we start uploading images, let’s look at what Reducto actually returns. This helps us understand what data we’re working with.Exploring chunks and blocks
Each chunk contains multiple blocks. A block can be text, a figure, a table, or other content types:Finding figures and tables
Let’s find all figures and tables in the document:Examining a figure block
Each figure block has several important fields:The
content field contains Reducto’s AI-generated description of the figure. This is incredibly useful, as it means your vector search can find figures based on what they show, not just the surrounding text.Step 3: Upload images to S3
Now we need to save these images permanently. Reducto’s URLs expire in 1 hour, so we’ll upload each image to S3 immediately.Initialize the S3 client
Determine the bucket region
S3 URLs include the region. If we get this wrong, the URLs won’t work:Create the upload function
This function downloads an image from Reducto and uploads it to S3:https://{bucket}.s3.{region}.amazonaws.com/{key}. Including the region is important, otherwise S3 may redirect requests, which can cause issues with some clients.
Upload all images
Now we loop through all chunks. For each chunk, we check if it contains any figures or tables. If it does, we upload those images to S3 and store the URLs. If it doesn’t, we still index the chunk but without an image URL. This is the key difference from image-only indexing: we index everything, both text-only chunks and chunks with figures.Verify an image is accessible
Let’s make sure our S3 URLs work:Step 4: Index into Pinecone
With images safely stored in S3, we can now create vector embeddings and store them in Pinecone.Initialize the clients
Understanding what we’re indexing
For each chunk, we store:- Vector: Embedding of the text (from
chunk.embed) - Metadata: Text preview, page number, and optionally an S3 image URL
Create embeddings and upsert
- For embeddings (
[:8000]): VoyageAI has input token limits - For metadata (
[:1000]): Pinecone has metadata size limits (~40KB per vector)
VoyageAI’s free tier has rate limits (3 requests per minute). For production use with many documents, add rate limiting or upgrade your plan.
Step 5: Query and retrieve
Now we can search our index. When someone asks a question, we:- Embed their query using the same model (voyage-3)
- Find the most similar vectors in Pinecone
- Return the matches with their S3 image URLs
Create the search function
Test the search
Step 6: Send to your LLM
You now have everything needed for multimodal generation:- Text context:
match.metadata["text"] - Image URLs:
match.metadata["image_url"](for chunks with images)
Reducto features for better results
These Reducto settings can improve your multimodal RAG pipeline:Figure summaries (enabled by default)
Figure summaries (enabled by default)
Reducto automatically generates AI descriptions of figures and includes them in the
embed field. This is why queries like “show me the revenue chart” can find relevant figures even if “revenue” doesn’t appear in surrounding text.This is controlled by summarize_figures (default: True). Keep it enabled for multimodal RAG.Agentic figure extraction
Agentic figure extraction
For documents with complex charts, enable agentic figure extraction for higher accuracy:This uses vision LLMs to better understand chart content. It adds latency and cost but improves extraction quality.
Embedding-optimized output
Embedding-optimized output
Enable
embedding_optimized for output specifically tuned for vector embeddings:Filter block types
Filter block types
If you only want certain content types, use
filter_blocks to exclude others from the embed field:Best practices
Choose the right chunking strategy
Choose the right chunking strategy
The
chunk_mode setting affects how figures relate to surrounding text:section: Groups content by document sections. Best for structured documents like research papers.page: One chunk per page. Simple and predictable.variable: Adaptive chunking based on content density.
section usually works best because it keeps figures with their explanatory text.Use the embed field for vector search
Use the embed field for vector search
Always use
chunk.embed (not chunk.content) for your vector embeddings. The embed field includes AI-generated figure descriptions that make visual content searchable.Not every query needs images
Not every query needs images
Sending images to your LLM adds latency and cost. Consider routing:
- Simple factual questions → Text-only RAG
- Questions about trends, comparisons, or visuals → Multimodal RAG
has_images in retrieved chunks before deciding which path to take.Handle rate limits gracefully
Handle rate limits gracefully
VoyageAI’s free tier has a 3 requests per minute limit. For production:
- Batch multiple texts in a single embedding call
- Add delays between calls
- Upgrade to a paid plan for higher limits
Limit retrieved images
Limit retrieved images
More images means higher LLM costs and slower responses. For most questions, 2-3 images is sufficient. Use
top_k=3 in your search function.Complete example
Here’s the full pipeline in a single script:Next steps
Batch Processing
Process multiple documents in parallel.
Chunking Methods
Learn about different chunking strategies.
Chart Extraction
Configure image extraction and other parse options.
Response Format
Understand the full parse response structure.