 [View the sample PDF in Studio](https://studio.reducto.ai/share/md726aw3w7mfs46659ttkqry0s7se3pd?processor=kh7c9e30evkfb5a4h80dq4xke17sfwck\&fileId=js7e4hrtnh2tsyjqdbz114ceyn7sf1v1) or [download it directly](https://cdn.reducto.ai/samples/fidelity-example.pdf) to follow along.
**What we want to extract:**
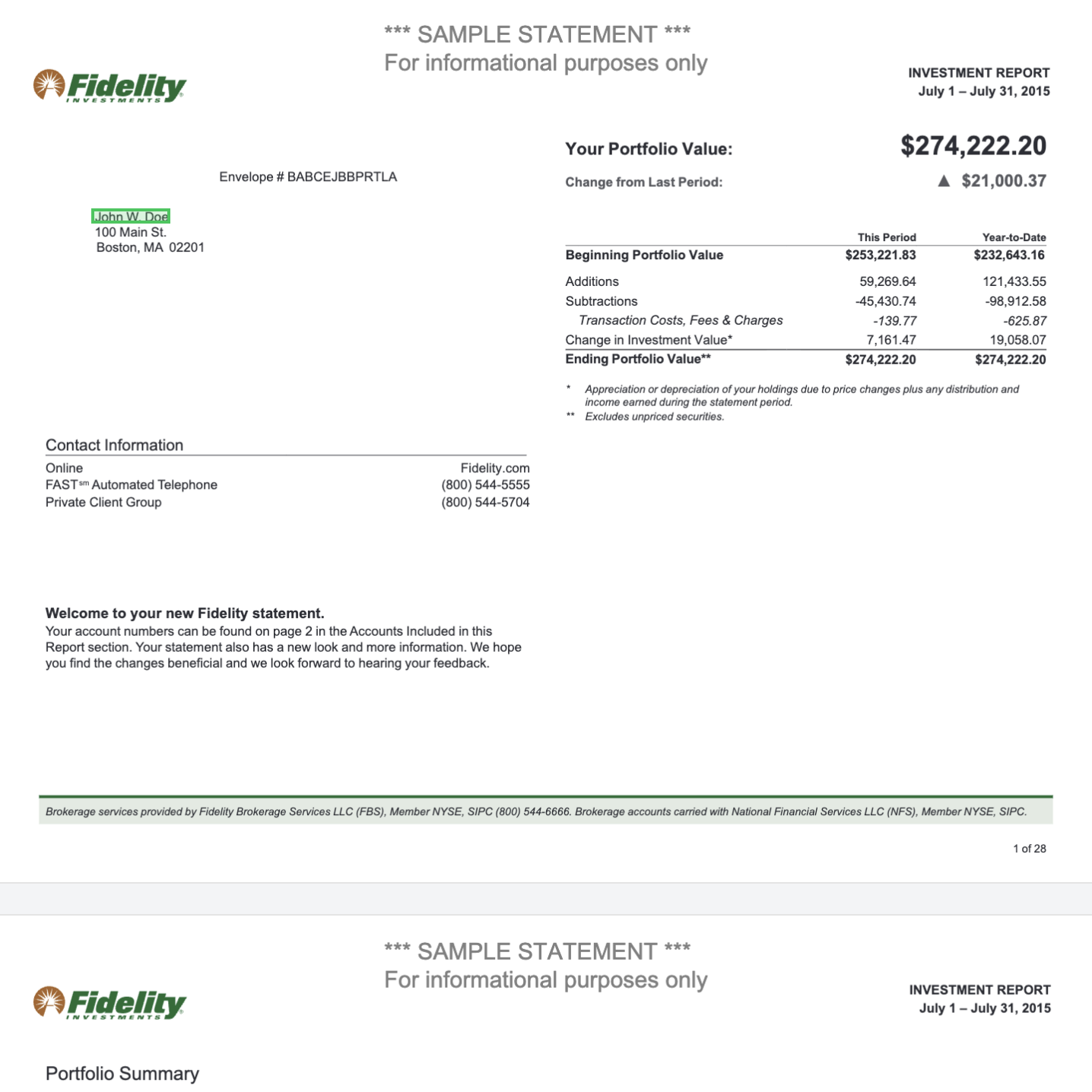
* The portfolio value table with beginning and ending values
* Account information including account numbers and types
* Income summary broken down by tax category
* Top holdings with values and percentages
By the end of this guide, you'll have all of this data in structured JSON that you can use in your application. For structured field extraction (e.g., extracting specific account numbers or values into typed fields), see the [/extract endpoint](/extract/overview) after completing this quickstart.
***
## Prerequisites
[View the sample PDF in Studio](https://studio.reducto.ai/share/md726aw3w7mfs46659ttkqry0s7se3pd?processor=kh7c9e30evkfb5a4h80dq4xke17sfwck\&fileId=js7e4hrtnh2tsyjqdbz114ceyn7sf1v1) or [download it directly](https://cdn.reducto.ai/samples/fidelity-example.pdf) to follow along.
**What we want to extract:**
* The portfolio value table with beginning and ending values
* Account information including account numbers and types
* Income summary broken down by tax category
* Top holdings with values and percentages
By the end of this guide, you'll have all of this data in structured JSON that you can use in your application. For structured field extraction (e.g., extracting specific account numbers or values into typed fields), see the [/extract endpoint](/extract/overview) after completing this quickstart.
***
## Prerequisites

````markdown theme={null}
## Add Reducto MCP Server
### 1. Authenticate (one-time)
```bash
uvx mcp-server-reducto --login
```
This opens your browser to approve access. Your API key is saved to `~/.reducto/config.yaml`.
### 2. Add to your MCP client
**Claude Code:**
```bash
claude mcp add reducto -- uvx mcp-server-reducto
```
**Claude Desktop**: edit `~/Library/Application Support/Claude/claude_desktop_config.json`:
```json
{
"mcpServers": {
"reducto": {
"command": "uvx",
"args": ["mcp-server-reducto"]
}
}
}
```
**Cursor**: edit `.cursor/mcp.json`:
```json
{
"mcpServers": {
"reducto": {
"command": "uvx",
"args": ["mcp-server-reducto"]
}
}
}
```
**VS Code**: edit `.vscode/mcp.json`:
```json
{
"servers": {
"reducto": {
"command": "uvx",
"args": ["mcp-server-reducto"]
}
}
}
```
### 3. Use it
The server provides these tools:
| Tool | What it does |
|------|-------------|
| `upload_file` | Upload a local file or URL to Reducto (returns `reducto://` URL) |
| `parse_document` | Parse a document into structured text, tables, figures |
| `extract_data` | Extract structured JSON from a document using a schema |
| `split_document` | Segment a document into labeled sections |
| `classify_document` | Categorize a document type |
| `edit_document` | Fill forms or modify a PDF/DOCX |
**Local files:** Use `upload_file` first, e.g. `upload_file("./report.pdf")`, then pass the returned `reducto://` URL to other tools.
**Chain operations:** `parse_document` returns a `job_id`. Pass `jobid://` to `extract_data` or `split_document` to skip re-parsing.
````